Instalación y configuración inicial de pacemaker | corosync en RH10
Resumen
Este manual presenta la instalación de un clúster de Pacemaker y Corosync de dos nodos en RHEL 10 (AlmaLinux). La configuración no contará con los servicios de fencing/STONITH, únicamente se realizará la configuración más básica posible, con una IP virtual (VIP) y un servicio web Apache. Se utilizará PCS siguiendo el manual oficial
Arquitectura
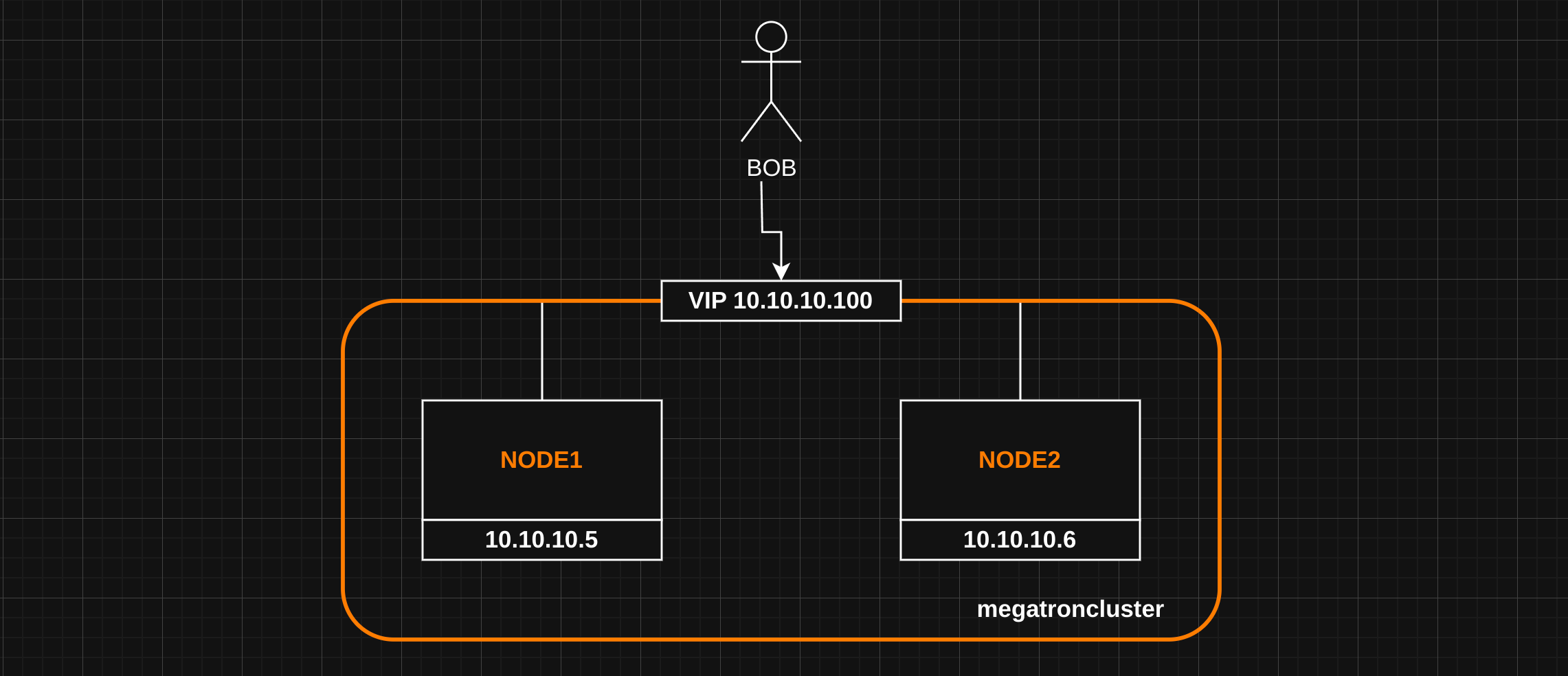
El cluster se compondrá de dos nodos [ node1 | node2 ].
Instalación inicial
Configuración inicial de los nodos
root@node1:~# hostnamectl
Static hostname: node1
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: 814d7fcf9faf4d688c112c9e9d089fb6
Boot ID: ca03f5039d9c42e38ac8c05e5bb3148e
Product UUID: eef6855a-4671-4f04-b818-f20b3977a18e
Virtualization: kvm
Operating System: AlmaLinux 10.0 (Purple Lion)
CPE OS Name: cpe:/o:almalinux:almalinux:10::baseos
OS Support End: Fri 2035-06-01
OS Support Remaining: 9y 9month 2w 3d
Kernel: Linux 6.12.0-55.24.1.el10_0.x86_64
root@node2:~# hostnamectl
Static hostname: node2
Icon name: computer-vm
Chassis: vm 🖴
Machine ID: 5d9ef93bd114429a848a07d9514150d3
Boot ID: f46b32d55404455aa6ffd91b7d989306
Product UUID: 1bd08f6f-6988-4367-998a-618a6cd7f94b
Virtualization: kvm
Operating System: AlmaLinux 10.0 (Purple Lion)
CPE OS Name: cpe:/o:almalinux:almalinux:10::baseos
OS Support End: Fri 2035-06-01
OS Support Remaining: 9y 9month 2w 3d
Kernel: Linux 6.12.0-55.24.1.el10_0.x86_64
Antes de comenzar a configurar el clúster, registrar los nombres en ambos nodos:
10.10.10.5 node1
10.10.10.6 node2
Instalación de Pacemaker
Para instalar Pacemaker es necesario activar los repositorios de alta disponibilidad. Seguir los siguientes pasos en ambos nodos:
dnf repolist --all
dnf config-manager --set-enabled highavailability
dnf update
dnf install pacemaker pcs
Configuración del usuario hacluster
Por defecto, una vez instalado Pacemaker, genera un usuario llamado hacluster. Es necesario cambiar la contraseña de este usuario, ya que será el encargado de gestionar el clúster:
root@node1:~# getent passwd hacluster
hacluster:x:189:189:cluster user:/var/lib/pacemaker:/sbin/nologin
Para este caso, ejecutar # passwd hacluster y modificar la contraseña.
Inicio del servicio pcsd
En ambos nodos es necesario arrancar el servicio pcsd.service:
root@node1:~# systemctl start pcsd
root@node1:~# systemctl enable pcsd
root@node1:~# systemctl status pcsd
● pcsd.service - PCS GUI and remote configuration interface
Loaded: loaded (/usr/lib/systemd/system/pcsd.service; disabled; preset: disabled)
Active: active (running) since Wed 2025-08-13 18:32:42 CEST; 5s ago
Invocation: 2680a56f287740d98f8ebec76a0b8df3
Docs: man:pcsd(8)
man:pcs(8)
Main PID: 11633 (pcsd)
Tasks: 31 (limit: 47376)
Memory: 459.4M (peak: 459.8M)
CPU: 6.654s
CGroup: /system.slice/pcsd.service
Creación del Clúster
Una vez configurado, el entorno estará listo para crear el clúster y dar de alta los nodos. Primero, generar las reglas en los firewall de ambos nodos:
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --reload
A partir de aquí, los comandos de PCS se realizarán solo en un nodo. Lo primero es autenticar ambos nodos con el usuario hacluster y la contraseña establecida anteriormente:
root@node1:~# pcs host auth node1 node2
Username: hacluster
Password:
node2: Authorized
node1: Authorized
Una vez autenticados, se puede crear el clúster. En este caso, se llamará al clúster megatroncluster. Después de esto, se debe arrancar de forma manual:
root@node1:~# pcs cluster setup megatroncluster node1 node2
root@node1:~# pcs cluster start --all
En caso de necesitar volver atrás se puede eliminar el cluster ejecutando # pcs cluster destroy. Una vez arrancado el cluster ya se puede ver el estado
root@node2:~# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: node1 (version 3.0.0-5.el10-7e73fd0) - partition with quorum
* Last updated: Wed Aug 13 19:03:52 2025 on node2
* Last change: Wed Aug 13 19:03:19 2025 by hacluster via hacluster on node1
* 2 nodes configured
* 0 resource instances configured
Node List:
* Online: [ node1 node2 ]
PCSD Status:
node2: Online
node1: Online
Verificación y Resolución de Errores en el Clúster
Si el clúster muestra errores con estado de nodo UNCLEAN, es necesario comprobar que el servicio pacemaker.service esté levantado. De lo contrario, PCS dará error.
Verificación del Servicio Pacemaker
# systemctl status pacemaker.service
# systemctl start pacemaker.service
# systemctl enable pacemaker.service
Configuración de Recursos en el Clúster
Deshabilitar STONITH
Dado que no se tiene instalado el agente de fencing, es necesario deshabilitar STONITH:
# pcs property set stonith-enabled=false
Crear Recurso de IP Virtual (VIP)
La IP virtual será la encargada de balancear el servicio en el nodo correcto. Los recursos se agruparán para que balanceen simultáneamente. En este caso, el grupo se llamará apachegroup:
root@node1:~# pcs resource create VirtualIP IPaddr2 ip=10.10.10.100 cidr_netmask=24 --group apachegroup
root@node1:~# pcs status
---
Full List of Resources:
* Resource Group: apachegroup:
* VirtualIP (ocf:heartbeat:IPaddr2): Started node1
Configuración del Servidor Web Apache
Instalación de Apache
Instalar Apache en ambos nodos:
dnf install -y httpd wget
Configuración del Archivo PID
Añadir la siguiente línea en /etc/httpd/conf/httpd.conf en ambos nodos:
PidFile /var/run/httpd/httpd.pid
Esta configuración es necesaria porque el proceso es controlado por systemd. La directiva PidFile especifica el archivo donde Apache almacena su ID de proceso principal (PID).
Configuración del Firewall
Añadir las siguientes reglas de firewall en ambos nodos:
firewall-cmd --permanent --add-service=http
firewall-cmd --permanent --zone=public --add-service=http
firewall-cmd --reload
Creación del Recurso Web en el Clúster
Siguiendo la guía oficial, crear el recurso de Apache:
pcs resource create Website apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apachegroup
Verificación del estado de los recursos
root@node1:~# pcs status
---
Full List of Resources:
* Resource Group: apachegroup:
* VirtualIP (ocf:heartbeat:IPaddr2): Started node1
* Website (ocf:heartbeat:apache): Started node1
Configuración y Depuración de Recursos
Verificar Configuración de Recursos
Para comprobar la configuración de los recursos individuales, utilizar los siguientes comandos:
root@node1:~# pcs resource config Website
root@node1:~# pcs resource config VirtualIP
Depuración de Recursos
En caso de problemas al iniciar los recursos, se puede utilizar el modo de depuración:
root@node1:~# pcs resource debug-start Website
Resultado Final del Clúster de Alta Disponibilidad
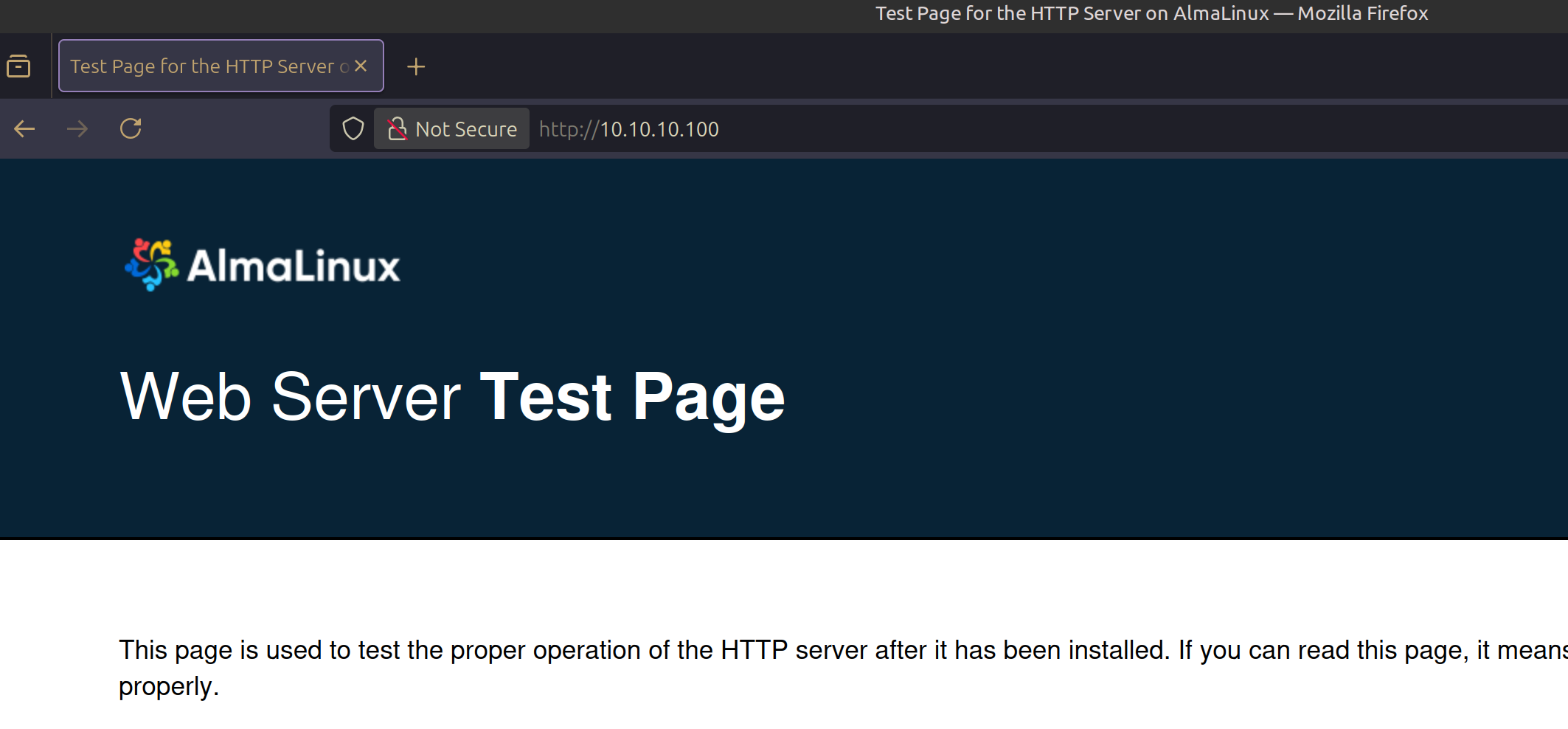
Acceso al Servicio Web
El servicio web estará accesible mediante la dirección IP virtual:
- URL:
http://10.10.10.100:80
Failover Automático
Escenario de Caída de node1
Cuando node1 se apaga, el clúster realiza automáticamente la migración de recursos:
root@node2:~# pcs status
---
Node List:
* Online: [ node2 ]
* OFFLINE: [ node1 ] <=================
Full List of Resources:
* Resource Group: apachegroup:
* VirtualIP (ocf:heartbeat:IPaddr2): Started node2
* Website (ocf:heartbeat:apache): Started node2
## Fuentes
- [ Guia oficial de Redhat ] https://docs.redhat.com/en/documentation/red_hat_enterprise_linux/8/html/configuring_and_managing_high_availability_clusters/assembly_creating-high-availability-cluster-configuring-and-managing-high-availability-clusters
- [ Resolución problema arranque apache ] https://serverfault.com/questions/915716/apache-failed-to-start-in-pacemaker